

「精度98%」「業務効率70%向上」「処理速度10倍」——。
AIツールの営業資料やプレスリリースには、こうした”魅力的な数字”が溢れています。
しかし、100を超えるAIツールを独立の立場から実機検証してきたAixisの結論は明確です。
これらの数字の大半は、あなたの会社では再現されません。
誤解しないでください。ベンダーが「嘘」をついているとは言いません。しかし、彼らが提示する数字には、意図的かどうかにかかわらず、「都合の良い前提条件」が織り込まれているケースが極めて多いのです。
本コラムでは、Aixisが検証現場で繰り返し目にしてきた「数字のトリック」を7つのパターンに類型化し、その構造を解剖します。AI導入を検討しているすべての企業に、ベンダーの数字を「読み解く力」を提供することが本稿の目的です。
なぜ今、この話をするのか
2025年のPwC Japan「生成AIに関する実態調査 5カ国比較」は、日本企業のAI導入において極めて示唆的なデータを突きつけました。
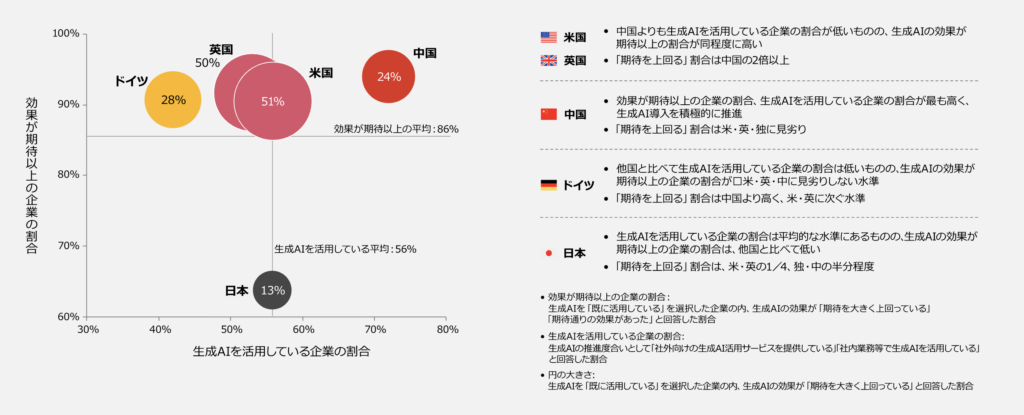
日本企業で生成AIの効果が「期待を大きく上回る」と回答した割合は、わずか13%。米国の51%、英国・ドイツ・中国と比較しても圧倒的に低い水準です。さらに深刻なのは、前回調査(2024年春)から「期待を下回る」と回答する企業が増加しており、二極化が解消されるどころか、悪化しているという事実です。
この「期待と現実のギャップ」が、なぜ埋まらないのか。
原因は複合的ですが、Aixisは一つの構造的な問題を指摘したい。導入前にベンダーから提示される「数字」が、実際の業務環境における性能を正しく反映していないという問題です。
ベンダーの数字を鵜呑みにして導入を決定し、実運用で「話が違う」となり、「やはりAIは使えない」という結論に至る。この悪循環が、日本企業のAI活用を停滞させている一因になっています。
パターン1:チェリーピッキング——「得意な問題だけで測る」
最も基本的、かつ最も蔓延しているトリックです。
AIツールには得意・不得意があります。当然、得意なタスクで測定すれば高い数字が出ます。ベンダーの営業資料に載る「精度98%」が、すべてのタスクの平均ではなく、最も成績の良かったタスクのスコアであるケースは珍しくありません。
この問題は、学術界でも実証されています。AAAI 2025(米国人工知能学会)で発表された論文では、時系列予測モデルの性能評価においてデータセットの選び方次第でモデルの見え方が大きく変わることが実証されています。都合の良いデータセットだけで評価すれば、どんなモデルでも「最高性能」に見せることが可能なのです。
実際にAixisが経験した事例を紹介します。
あるAI-OCR(文字認識)ツールのベンダーは、営業資料で「読み取り精度99.2%」を謳っていました。しかしAixisが独自検証したところ、この数字は活字の請求書テンプレートでの測定値でした。手書きの注文書、FAXで送られた発注書、スタンプ印が重なった領収書——実際の業務で処理される「汚い書類」では、精度は70%台まで低下しました。
「99.2%」と「70%台」。同じツールの、同じ機能の話です。
なぜこれが問題なのか
AIツールの導入を検討する企業の担当者は、当然ながら「99.2%」を前提にROI計算を行います。その数字で稟議を通し、予算を確保します。しかし実運用で70%台の精度しか出なければ、人手による修正作業が発生し、想定していたコスト削減効果は大幅に縮小します。
問題は、ベンダーが嘘をついているわけではないという点です。99.2%は、特定の条件下では確かに出る数字です。だからこそタチが悪い。ベンダーが提示する数字は「嘘」ではなく「一部の真実」なのです。
パターン2:比較対象の恣意性——「誰と比べるか」で数字は変わる
「従来の手作業と比較して業務効率70%向上」。
この手の数字を見たとき、真っ先に確認すべきは「従来」とは何かという定義です。
Aixisが見てきた営業資料の多くで、比較対象として設定されていたのは「すべてを手作業で行った場合」でした。しかし現実の業務現場では、すでにExcelマクロやRPA、既存の業務システムが稼働しています。完全な手作業と比較すること自体が、そもそも非現実的な前提です。
ある文書分類AIの導入提案で、ベンダーは「分類作業の工数を80%削減」と主張していました。Aixisが確認したところ、比較対象は「担当者が1件ずつ目視で分類する場合」でした。しかし、その企業ではすでにルールベースの自動振り分けが導入されており、手動で分類しているのは全体の30%程度。AIツールが実際に置き換える業務は全体の30%のうちの80%、つまり全体工数に対するインパクトは24%に過ぎませんでした。
「80%削減」と「24%削減」。経営判断は180度変わります。
パターン3:テスト環境と本番環境の乖離——「理想の実験室」で出た数字
AI業界の構造的な問題として、2026年1月時点で研究者らが大規模な調査を行い、主要AIモデルのベンチマークスコアが100ポイント以上も水増しされている実態が明らかになっています。各社が自社のベストバリアントのみを選んで提出し、評価を「軍拡競争」に変えてしまっていた、というものです。
これはモデル開発者同士の話ですが、企業向けの営業でも構造は同じです。
ベンダーのデモ環境は「理想の実験室」です。ネットワーク遅延はない。データはクリーンに前処理されている。エッジケース(例外的なデータ)は除外されている。同時アクセス負荷もかからない。
Aixisがある議事録作成AIを検証した際、ベンダーのデモでは静かな会議室で2人が交互に発言する環境が使われていました。しかし、実際の会議室では空調音があり、複数人が同時に発言し、方言やカタカナ語が飛び交います。デモ環境で「認識精度95%」だったツールは、リアルな会議環境では60%台まで低下しました。
パターン4:「平均値」のマジック——外れ値が隠す真実
「平均回答精度92%」。
この数字は一見頼もしく見えます。しかし、重要なのは分散です。
100件の質問のうち、90件で精度100%、10件で精度12%の場合、平均は約91%になります。しかし実務において、10件に1件が壊滅的に間違えるAIは使い物になりません。
特に問題なのは、この「壊滅的に間違える10%」が、しばしば業務上最も重要なケースに集中することです。簡単な定型処理は正確にこなすが、例外処理やイレギュラーケースでは崩壊する。そして、例外処理こそが人間の判断を本当に必要とする場面であり、だからこそAIに任せたかった場面です。
Aixisが検証したある契約書レビューAIは、「レビュー精度90%超」を謳っていました。確かに、標準的な契約書テンプレートに対しては高精度で動作しました。しかし、個別交渉で修正された特殊条項——まさに法務部門が最も注意すべき箇所——の検出率は50%を下回っていました。
平均値では見えない。しかし、平均値の外側にこそリスクがある。
パターン5:指標のすり替え——「精度」と「正解率」は違う
技術的な話になりますが、極めて重要な論点です。
AIの性能を測る指標は一つではありません。「精度(Precision)」「再現率(Recall)」「F1スコア」「正解率(Accuracy)」——これらは似ているようで、まったく異なる意味を持ちます。
そしてベンダーは、最も数字が高く見える指標を選んで提示する傾向があります。
最もわかりやすい例が、不正検知AIです。
仮に1万件の取引のうち、不正取引が10件だとします。この場合、すべてを「正常」と判定するだけで正解率は99.9%になります。しかしこのAIは、不正を1件も検出していません。「正解率99.9%」という数字だけを見れば素晴らしいAIに見えますが、そもそもの目的である不正検知においては完全に無価値です。
これは極端な例ですが、実際の営業現場では、このような指標のすり替えが巧妙な形で行われています。ベンダーに「この精度はどの指標で測っていますか?」と質問した際に、明確に回答できない営業担当者がいたら、それ自体が警告サインです。
パターン6:時間軸の省略——「導入直後の数字」と「半年後の数字」
AIモデルの性能は、時間とともに劣化します。
これは「モデルドリフト」と呼ばれる現象で、AIの学習データと実際のデータの分布が時間の経過とともにずれていくことで発生します。季節変動、市場環境の変化、法改正、顧客層の変化——あらゆる外部要因がモデルの精度に影響します。
しかし、ベンダーの営業資料に記載される数字は、ほぼ例外なく「導入直後」のベストスコアです。半年後、1年後にどこまで精度が維持されるかは通常言及されません。
Aixisが追跡調査を行ったある需要予測AIでは、導入時の予測精度は「MAPE(平均絶対パーセント誤差)8%」と優秀でした。しかし半年後、COVID以降の消費者行動の変化やサプライチェーンの変動により、MAPEは23%まで悪化していました。再学習のための追加コストは当初見積もりに含まれておらず、企業は想定外の出費を強いられました。
ベンダーに聞くべきは「今の精度」ではなく「半年後の精度をどう保証するか」です。
パターン7:「導入事例」の生存者バイアス——見せられるのは成功だけ
最後に、数字そのものではなく、数字が載る「場所」の問題です。
ベンダーのウェブサイトに掲載される導入事例は、当然ながら成功事例だけです。これは生存者バイアスの教科書的な事例です。10社に導入して3社で成功、7社で期待通りにいかなかったとしても、ウェブサイトには3社の事例だけが輝かしく掲載されます。
しかも、導入事例に記載される「効果」は、多くの場合導入企業の自己申告に基づいています。導入を推進した担当者が「失敗でした」と社外に向けて発表するインセンティブはありません。むしろ、自分が推進した案件を「成功」として語るインセンティブが強く働きます。
PwCの2025年調査に戻れば、日本企業で生成AI活用が「期待を下回る」と回答した企業が増加しています。しかし、この「期待を下回った」企業の声が、ベンダーの導入事例として表に出ることはありません。
私たちが見せられている「成功事例」は、氷山の一角です。
では、どうすればいいのか——Aixisの提言
ここまで7つのパターンを解剖してきましたが、「ベンダーが悪い」という単純な話にするつもりはありません。
ベンダーは自社製品を売ることが仕事です。自社製品の最も良い面を見せるのは、ビジネスとして当然の行為です。自動車メーカーがカタログに最も美しい写真を載せるのと同じです。問題なのは、AIツールの場合、その数字の「前提条件」を検証する仕組みが市場に存在しないことです。
自動車には公的な燃費測定基準があります。WLTCモードという共通の測定方法があるから、消費者は異なるメーカーの車を同じ土俵で比較できます。金融商品には目論見書の開示義務があります。リスクとリターンの両面が、規制のフレームワークの下で開示されます。
しかしAIツールにはそれがありません。ベンダーが自社で設定した条件で、自社で測定した数字を、自社で選んだ形式で開示している。これは「情報の非対称性」の最たるものです。
この問題に対して、米国では連邦取引委員会(FTC)が動き出しています。2025年4月、AIコンテンツ検出ツールを提供するWorkadoに対して、「精度98%」という広告が虚偽であるとして行政処分を下しました。独立した第三者のテストでは、同ツールの精度はわずか53%——コイントスと変わらない水準でした。FTCの消費者保護局ディレクターは、AIに関するミスリーディングな主張は正当な競争を歪めるものだと指摘しています。
日本にはまだこうした規制の動きはありません。しかし、規制を待つ必要はありません。
ベンダーに必ず確認すべき5つの質問
1.「この数字は、どのデータセットで測定しましたか?」 自社の業務データに近い条件で測定されたものかを確認します。ベンダーが用意したクリーンなデモデータでの数字は、参考程度にしかなりません。
2.「測定に使った指標の定義を教えてください」 「精度」が何を意味するのか。Precision なのか Accuracy なのか F1 なのか。定義が曖昧な場合、その数字には意味がありません。
3.「比較対象は何ですか?」 「○○%向上」の起点が何かを確認します。完全な手作業との比較なのか、既存システムとの比較なのかで、意味はまったく異なります。
4.「最悪のケースではどうなりますか?」 平均値ではなく、ワーストケースを聞きます。業務上致命的になりうる場面で、どの程度の性能が出るかが真に重要です。
5.「モデルの精度を維持するためのコストと体制は?」 導入時の精度だけでなく、運用フェーズでの再学習や追加コストを含めた総コストを確認します。
Aixisが存在する理由
ここまで読んだ方は、一つの疑問を持つかもしれません。
「そうは言っても、自社でベンダーの数字を検証する専門知識もリソースもない」
まさに、その問題を解決するためにAixisは存在しています。
自動車を買うとき、販売店の営業担当の言葉だけで数百万円を払う人はいません。第三者のレビューを読み、試乗し、公的な安全性評価を確認します。しかしAIツールの選定では、ベンダーの営業資料と自社での短期間のトライアルだけで、数百万円から数千万円の意思決定が行われています。
Aixisは、AIツールベンダーから完全に独立した第三者の監査機関です。ベンダーから金銭を受け取ることは一切ありません。ベンダーの数字を「あなたの会社の業務データ」で検証し、ベンダーが提示しない情報——精度の分散、エッジケースでの挙動、運用コストの全体像——を明らかにします。
ベンダーの営業資料に書かれた「精度98%」が、あなたの会社で本当に再現されるのか。それを確かめる方法は、ベンダーでもなく、あなた自身でもなく、独立した第三者に検証させることです。
「この数字、本当ですか?」——その問いに答えるのが、Aixisの仕事です。
→ AIツールの”数字”に疑問を感じたら:Aixis スポット監査サービス
出典・参考文献
- PwC Japan グループ「生成AIに関する実態調査2025 春 5カ国比較 ―進まない変革 グローバル比較から読み解く日本企業の活路―」
- PwC Japan グループ「生成AIに関する実態調査2024 春 米国との比較」
- 総務省「令和7年版 情報通信白書:企業におけるAI利用の現状」
- 財務省 大臣官房総合政策課「経済トレンド 134:生成AI導入はゴールではない」
- U.S. Federal Trade Commission “FTC Order Requires Workado to Back Up Artificial Intelligence Detection Claims”(2025年4月)
- Roque, L. et al. “Cherry-Picking in Time Series Forecasting: How to Select Datasets to Make Your Model Shine” Proceedings of the AAAI Conference on Artificial Intelligence, Vol.39(19), 2025
- LMArena benchmark manipulation analysis(2026年1月:280万レコードの分析)
- Stanford HAI “AI Index Report 2025”
- NIST AI Risk Management Framework (AI RMF) / ISO/IEC 42006:2025