

2026年4月の新年度を前に、生成AIの社内ガイドライン策定や改訂に着手する企業が増えています。
しかし、総務省が2025年に実施した調査によれば、日本企業で「積極的に活用する方針」または「活用する領域を限定して利用する方針」を定めている企業の割合は49.7%にとどまっています(出典:総務省「国内外における最新の情報通信技術の研究開発及びデジタル活用の動向に関する調査研究」)。特に中小企業では約半数が「方針を明確に定めていない」と回答しており、ガバナンスの整備は依然として途上にあります。
ガイドラインの「不在」は情報漏洩や著作権侵害といった具体的なリスクを放置することになります。一方で、ガイドラインを「作っただけ」で現場に定着しない形骸化のケースも少なくありません。
本記事では、政府公式ガイドラインや最新の調査データを基に、実効性のある生成AI社内ガイドラインの策定手順、盛り込むべき構成要素、そして運用段階で陥りがちな落とし穴までを体系的に解説します。
なぜ今、生成AI社内ガイドラインの策定が急務なのか
企業の生成AI導入は加速、しかしガバナンスは追いついていない
企業における生成AIの利用は急速に拡大しています。一般財団法人日本情報経済社会推進協会(JIPDEC)と株式会社アイ・ティ・アール(ITR)が実施した「企業IT利活用動向調査2024」によれば、「会社で構築・契約した生成AIを使用している」企業が15.9%、「各自で契約・登録した生成AIを使用している」企業が19.1%となり、合計で35.0%の企業が業務で生成AIを使用しています。さらに34.5%の企業が「会社として生成AIの導入を進めている」と回答しており、今後さらに利用企業は増加する見込みです。
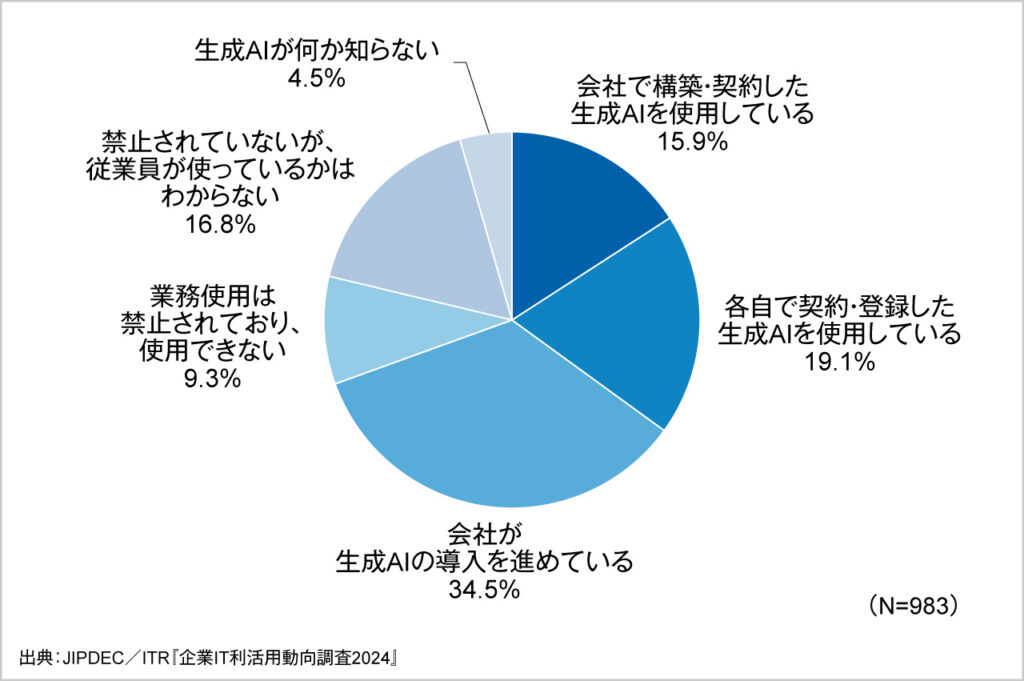
問題は、この普及スピードにガバナンスの整備が追いついていない点にあります。同調査では、会社で構築・契約した生成AIを使用している企業のガイドライン策定率は68.6%に達する一方、各自で契約・登録した生成AIを使用している企業ではこの割合が大きく低下することが報告されています。つまり、従業員個人が登録した生成AIが管理外で使われている、いわゆる「シャドーAI」のリスクが顕在化しているのです。
また、IIJが情報システム部門を対象に実施した調査では、生成AIガイドラインが「未整備」と回答した企業は63%に達しました。現場からは「ルールを決められるほどの情報がない」「どの範囲をカバーすべきか判断が難しい」といった声が寄せられており、策定のノウハウ不足が大きな壁になっていることがうかがえます。
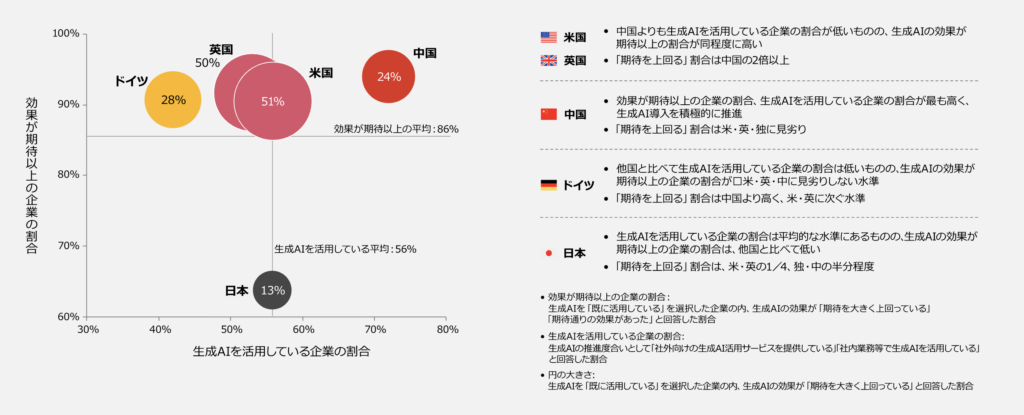
国際比較でも日本の課題は鮮明です。PwC Japanグループの「生成AIに関する実態調査2025春 5カ国比較」によれば、日本の生成AI導入度は平均的な水準にあるものの、効果実感は低く、「期待を上回る」と回答した企業の割合は米国・英国の約4分の1にとどまっています。ガバナンス体制の弱さが活用効果のボトルネックになっている構図です。
ガイドライン不在が招いた情報漏洩事故
ガイドラインが整備されていない環境で生成AIを使い続けるリスクは、すでに具体的な事故として表面化しています。
代表的な事例が、2023年に韓国の大手電子機器メーカーで発生したインシデントです。エンジニアが開発中のソースコードをChatGPTに入力し、デバッグを依頼したところ、入力された情報がAIの学習データとして外部に取り込まれる可能性が発覚しました。学習への利用を拒否するオプトアウト設定がなされていなかったことが問題を深刻化させ、同社はその後、社内での生成AI利用を全面的に制限する措置を講じています。
2023年3月にはChatGPT自体のシステムバグにより、一部のユーザーが他のユーザーのチャット履歴タイトルを閲覧できる状態になるインシデントが発生しました。後の調査では、有料会員の氏名、メールアドレス、クレジットカード番号の一部と有効期限も閲覧可能になっていたことが判明しています。
また、シンガポールのセキュリティ企業Group-IBは2023年6月、10万件を超えるChatGPTアカウントの認証情報がダークウェブ上で売買されていることを報告しました。情報窃取型マルウェア(インフォスティーラー)に感染した端末から盗まれたもので、日本からの漏洩も約660件確認されています。2025年2月にも、OpenAIのアカウント認証情報とされる約2,000万件のデータがダークウェブ上に出品される事例が確認されました。
これらの事故が示すのは、生成AIのリスクは「入力データの管理」だけでなく、「アカウント管理」「端末セキュリティ」「ツール側の脆弱性」など多層的であるという事実です。包括的な社内ガイドラインなしにこうしたリスクに対処することは極めて困難です。
新年度は策定・改訂の最適タイミング
2025年5月には「人工知能関連技術の研究開発及び活用の推進に関する法律」(AI基本法)が成立し、同年9月に全面施行されました。今後、内閣に設置された人工知能戦略本部により「人工知能基本計画」および「指針」が策定される予定です。加えて、経済産業省・総務省の「AI事業者ガイドライン」も2025年3月に第1.1版へと改訂されています。
法制度環境が大きく動いている今、4月の新年度に合わせたガイドラインの策定・改訂は、組織改編や予算編成のタイミングとも重なり、経営層の意思決定を得やすい好機です。
社内ガイドライン策定前に押さえるべき公的ガイドライン5選
社内ガイドラインをゼロから作る必要はありません。信頼性の高い公的ガイドラインを参照することで、抜け漏れを防ぎ、策定の効率を大幅に高められます。ここでは、社内ガイドライン策定時に必ず参照すべき5つの公的文書を、それぞれの特徴と社内ルールへの活かし方とともに紹介します。
① 経済産業省・総務省「AI事業者ガイドライン」(第1.1版、2025年3月)
AI開発者・AI提供者・AI利用者の3者に向けた統一的な指針を定めた、日本のAIガバナンスの最上位文書です。もともと2024年4月に第1.0版が公表され、2025年3月に第1.1版へ改訂されました。
社内ガイドラインとの関係では、「AI利用者」に求められる責務(適正利用、セキュリティ確保、プライバシー保護など)を、具体的な社内ルールへ翻訳するための基盤となります。本編で「何をすべきか」(指針=What)を確認し、別添の付属資料で「どう取り組むか」(実践=How)を参照するという使い方が有効です。
出典:https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html
② JDLA「生成AIの利用ガイドライン」(第1.1版)
一般社団法人日本ディープラーニング協会(JDLA)が公開する、社内ガイドラインのひな形として最も広く参照されている文書です。2023年5月に第1版が公開され、同年10月に第1.1版へ改訂されました。
ゼロからガイドラインを策定する場合、このひな形をベースに自社の業種・規模・利用目的に応じてカスタマイズしていくアプローチが最も効率的です。IIJの調査でも、ガイドライン整備済みの企業の多くがJDLAやデジタル庁の公的ガイドラインを参考に策定していることが報告されています。
出典:https://www.jdla.org/news/20230501001/
③ IPA「テキスト生成AIの導入・運用ガイドライン」(2024年7月)
独立行政法人情報処理推進機構(IPA)の産業サイバーセキュリティセンターが策定した、セキュリティリスクに特化したガイドラインです。JDLAのガイドラインが「利用者」を対象とするのに対し、IPAのガイドラインは「組織でテキスト生成AIを導入・運用する担当者」を対象としており、より実務的な内容になっています。
特筆すべきは、従来の生成AIのセキュリティリスクだけでなく、RAG(Retrieval-Augmented Generation、検索拡張生成)を企業で導入する際に新たに発生するセキュリティリスクについても詳述している点です。リスクアセスメントの手法が具体的に示されているため、社内でのリスク評価にそのまま活用できます。
出典:https://www.ipa.go.jp/jinzai/ics/core_human_resource/final_project/2024/generative-ai-guideline.html
④ デジタル庁「テキスト生成AI利活用におけるリスクへの対策ガイドブック(α版)」
行政機関を主な対象として策定されたものですが、生成AIのリスクを体系的に分類している点で、民間企業にとっても有用な参照文書です。リスクの洗い出しを行う際の枠組みとして活用できます。
出典:https://www.digital.go.jp/resources/generalitve-ai-guidebook
⑤ 文化庁「AIと著作権に関する考え方について」(2024年3月)
生成AIと著作権の関係について、文化審議会著作権分科会法制度小委員会が取りまとめた文書です。生成AIの利用を「開発・学習段階」と「生成・利用段階」の2段階に分け、それぞれの段階で著作権法がどのように適用されるかを整理しています。
社内ガイドラインで著作権に関するルールを定める際の最重要参照文書です。2024年7月には、より実務的な「AIと著作権に関するチェックリスト&ガイダンス」も公開されており、ステークホルダーの立場ごとに望ましい取り組みが分かりやすくまとめられています。
出典:https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/pdf/94037901_01.pdf
【参考】海外の規制動向
EUでは2024年5月にAI規則(EU AI Act)が成立し、2030年12月までに段階的に施行されます。AIをリスクレベルに応じて分類し、高リスクのシステムには厳格な要件を課すこの規制は、グローバルに事業を展開する企業にとって無視できない指針です。また、G7/OECDの広島AIプロセスでは、2025年2月に報告枠組みの運用が開始されました。海外拠点を持つ企業や、グローバルクライアントと取引のある企業は、これらの動向も社内ガイドラインに反映させることを推奨します。
社内ガイドラインに盛り込むべき10の構成要素
JDLAのひな形や公的ガイドラインを参考に、社内ガイドラインに盛り込むべき構成要素を10項目に整理しました。各要素について、「なぜ必要か」「定めないとどうなるか」を合わせて解説します。
1. 目的・適用範囲の定義
ガイドラインの冒頭で、策定の目的(生成AIの安全かつ効果的な活用の推進)と適用範囲を明確にします。対象とするツール(ChatGPT、Microsoft Copilot、Google Gemini、Claude など)を具体名で列挙し、「本ガイドラインに記載のないAIツールの業務利用は事前申請を必要とする」といったキャッチオール条項を設けることで、新しいツールが登場した際にも対応できる設計にしておくことが重要です。
業務利用と私的利用の境界線も明示します。例えば「業務用端末での利用は全てガイドラインの適用対象とする」といった基準を設けることで、判断の曖昧さを排除できます。
2. 利用が許可される業務範囲
禁止事項の列挙だけでは従業員の萎縮を招き、かえって管理外での利用(シャドーAI)を助長するリスクがあります。「どのような業務で積極的に使ってよいか」という推奨用途を具体的に明示することが、利活用促進とリスク管理の両立に不可欠です。
推奨用途の例としては、文書の要約・校正、アイデア出し・ブレーンストーミング、プログラムコードの補助、外国語の翻訳・ドラフト作成などが挙げられます。一方、最終的な意思決定への直接利用、人事評価への利用、顧客への直接送付(人間のレビューなし)などは、リスクに応じて制限・禁止とするのが一般的です。
3. 入力データの分類と制限ルール
社内の情報資産を分類基準(機密・社外秘・社内限定・公開など)に基づいて整理し、分類レベルごとに生成AIへの入力可否を明確にします。これは前述のサムスン電子の事例が示す通り、ガイドラインで最も重要な項目の一つです。
「機密情報は入力しないこと」というルールだけでは不十分です。何が機密情報に該当するのかの判断基準が個人によって異なるため、具体例を示す必要があります。例えば、顧客名・取引先名、未公開の財務情報、ソースコード、特許出願前の技術情報、個人情報(氏名・連絡先・マイナンバー等)といった具体的なカテゴリを明記することで、現場の判断ミスを防止できます。
4. データ学習・オプトアウト設定の管理
生成AIサービスの多くは、デフォルト設定ではユーザーの入力データをモデルの学習に利用する仕様になっています。法人契約(API利用やEnterprise契約)と、従業員が個人で登録した無料・個人プラン契約では、データの取り扱いポリシーが大きく異なります。
ガイドラインでは、業務利用するツールについてオプトアウト設定の確認・適用を義務付けるとともに、可能な限り法人向けの契約を利用し、入力データが学習に使用されない環境で利用することを推奨します。
5. 出力結果の検証・ファクトチェック義務
生成AIが事実と異なる情報をあたかも正しい情報であるかのように出力する「ハルシネーション」は、現在の技術では完全には防げません。ガイドラインにおいて「AIの出力結果はあくまで下書き・たたき台であり、最終的な判断・確認は人間が行う」という原則を明文化することが必要です。
特に、社外に公開する文書や、経営判断に使用するデータについては、出典の確認と事実関係の検証プロセスを義務付けます。
6. 著作権・知的財産権に関するルール
文化庁の「AIと著作権に関する考え方について」に基づき、生成AIの出力物を利用する際の著作権リスクを社内ルールに落とし込みます。特に注意すべきは、著作権侵害が成立する要件である「類似性」と「依拠性」の概念です。生成AIの学習データに既存の著作物が含まれている場合、出力物が当該著作物に類似していれば、利用者が既存の著作物を認識していなくとも依拠性が推認されうるとされています。
実務的には、生成AIの出力物を商用利用する前に、既存の著作物との類似性を確認するプロセスを設けることが望ましいでしょう。画像生成AIについては特にリスクが高いため、商用利用時のチェックフローを別途定めることを推奨します。
7. 個人情報保護に関するルール
個人情報保護法との整合を確保するため、顧客データや従業員の個人情報を生成AIに入力することを原則禁止とします。やむを得ず個人情報を扱う場合は、匿名化・仮名化の処理手順を定め、事前承認を必須とします。
8. 利用ログの記録・モニタリング
ガイドラインが形骸化する最大の原因は、「誰が・いつ・どのツールで・何をしたか」が把握できない状態にあることです。利用ログの記録と定期的なモニタリングの仕組みを整備することで、ルール遵守の実態を可視化し、監査対応の基盤を構築します。
利用申請のテンプレートを統一しておくことも有効です。利用目的、対象ツール、入力データの分類レベルを事前に記録する仕組みがあれば、インシデント発生時の原因追跡も容易になります。
9. インシデント発生時の対応手順
万が一、機密情報を誤って生成AIに入力してしまった場合や、出力物が著作権侵害に該当する可能性がある場合の、エスカレーションフローを定めます。「誰に」「何を」「いつまでに」報告するかを具体的に明記し、従業員が萎縮して報告を躊躇することのないよう、懲罰ではなく再発防止を重視する姿勢を明示することも重要です。
10. 定期的な見直し・改訂のルール
生成AI技術は日進月歩で進化しており、法制度も急速に整備が進んでいます。策定時には想定していなかったツール、機能、リスクが次々と登場するため、ガイドラインの見直しサイクル(最低年1回、理想は四半期ごと)を明記します。改訂時には、法務・情報システム・人事・事業部門の各ステークホルダーが参画する体制を維持することが、実効性の確保に不可欠です。
ガイドライン策定の5ステップ
構成要素を理解した上で、具体的にどのようなプロセスでガイドラインを策定すればよいのかを5つのステップで解説します。
STEP1:現状把握──利用実態の調査とリスクの洗い出し
まず、自社における生成AIの利用実態を把握します。社内アンケートやヒアリングを通じて、どの部門が・どのツールを・どのような業務に使用しているかを調査します。IPAの「テキスト生成AIの導入・運用ガイドライン」に記載されているヒアリング項目が参考になります。
この段階で特に注意すべきは、管理部門が把握していない「シャドーAI」の実態です。従業員が個人のアカウントで登録した生成AIを業務に使用しているケースは珍しくなく、利用実態の把握なくしてガイドラインを策定しても、現場の実情と乖離したルールになりかねません。
STEP2:策定体制の構築──部門横断チームの立ち上げ
ガイドラインは特定の部門だけで策定するものではありません。情報システム部門(技術的観点)、法務部門(法的リスク)、人事部門(教育・研修)、事業部門(現場の利活用ニーズ)が横断的に参画するチームを編成します。
経営層のコミットメントも不可欠です。PwCの調査が示す通り、効果を上げている企業に共通するのは、経営陣のリーダーシップの下で生成AIを組織全体に統合し、ガバナンス整備と全社的変革を進めている点です。策定チームの活動を経営層が明確にバックアップする体制を確保してください。
STEP3:ドラフト作成──ひな形のカスタマイズ
JDLAの「生成AIの利用ガイドライン」をベースに、前章で解説した10の構成要素を自社の業種・規模・利用目的に合わせてカスタマイズしていきます。AI事業者ガイドライン第1.1版の指針をチェックリストとして使い、抜け漏れがないか確認するのも有効です。
ドラフト作成時のポイントは、「禁止リスト」だけでなく「推奨リスト」を充実させることです。厳しすぎる制限はかえって無断利用を招く原因となり、リスク管理の本来の目的に反します。
STEP4:レビュー・承認──法務チェックと経営承認
ドラフトが完成したら、法務部門による法的リスクチェック、情報システム部門による技術的実現可能性の検証を経て、経営会議やリスク管理委員会での正式承認を取得します。この承認プロセスを経ることで、ガイドラインに組織としての正当性が付与され、全社展開時の説得力が増します。
STEP5:全社展開・教育──「知っている」から「実践できる」へ
ガイドラインの全社展開では、文書の配布だけでなく、理解と実践を促す教育施策が重要です。部門ごとの説明会、具体的な利用シーンに基づいたケーススタディ研修、eラーニングによる定期的な復習といった複数のアプローチを組み合わせます。
参考事例として、富士通は自社の「生成AI利活用ガイドライン」(第1.2版、2024年7月)を社外にも公開しています。社内向けに作成したガイドラインを広く公開することで、透明性を高めるとともに、他組織にとっての参考資料としても活用されています。こうした先進的な取り組みも、自社のガイドライン策定・運用の参考になるでしょう。
「作っただけ」で終わらせない──運用段階の3つの落とし穴と対策
ガイドラインの策定はゴールではなくスタートです。多くの企業が策定後に直面する運用上の課題を3つ取り上げ、それぞれの対策を解説します。
落とし穴①:形骸化──ルールが現場の実態と乖離する
生成AIの技術進化は極めて速く、数ヶ月前のルールが現在の利用実態に合わなくなることは珍しくありません。1年前に作ったガイドラインをそのまま放置すれば、現場は「ルールが実態に合っていない」と判断し、独自の運用を始めてしまいます。
IIJの調査でも、現場の担当者から「ルールを決められるほどの情報がない」「どの範囲を整備すべきか判断が難しい」という声が寄せられています。この問題の根本原因は、ガイドラインの策定を「一度きりのプロジェクト」と捉えてしまうことにあります。
対策: ガイドラインの見直しを四半期ごとの定期業務として組み込み、新ツールの導入時や重大インシデントの発生時には都度更新を行う体制を構築します。IPAのガイドラインが推奨するPDCAサイクル──「スモールスタート」→「本格導入」→「改善」のプロセスをガイドラインの運用にも適用することが有効です。
落とし穴②:ベンダー依存──ツール選定が客観性を欠く
ガイドラインの策定と並行して進むAIツールの選定において、特定のベンダーの情報提供に依存してしまうケースが散見されます。ベンダーが提供するセキュリティ資料や比較表は、自社に有利な評価軸で作成されていることが多く、客観的な判断材料としては不十分です。
ガイドラインが特定のツールに依存した設計になると、他のツールへの乗り換えや比較検討が困難になり、結果としてベンダーロックインに陥るリスクがあります。
対策: ガイドラインはツール非依存の原則で設計し、特定のサービス名ではなく「テキスト生成AI」「画像生成AI」などの機能カテゴリで規定します。ツールの選定・評価には、ベンダーの自己申告だけでなく、客観的な評価基準に基づいた検証プロセスを設けることが重要です。この際、ベンダーとの利害関係のない第三者による検証を活用することで、評価の信頼性を担保できます。
落とし穴③:自己評価の限界──自社だけでは気づけないリスク
生成AIのリスクは日々進化しています。NTTデータの解説記事では、従来のプロンプトを通じた情報入力だけでなく、MCP(Model Context Protocol)などのコネクタを介したシステム間通信により、意図しない機密情報が生成AIに漏洩する新たなリスクも指摘されています。
社内の限られた知見だけでは、こうした最新のリスクに対応することが難しいのが現実です。自社でガイドラインを策定・運用していても、「本当にこれで十分なのか」「見落としているリスクはないか」という不安は、多くの企業で共有されている課題ではないでしょうか。
対策: 社内の自己評価に加え、定期的に外部の専門家による監査・検証を受けることで、自社だけでは気づけない盲点を補完します。特に、ツール選定の妥当性やセキュリティ対策の十分性については、ベンダーから独立した第三者の視点が有効です。
まとめ
新年度を機にガイドラインの策定・改訂に着手することは、AI基本法の施行やAI事業者ガイドラインの改訂が進む今、タイミングとして非常に適切です。本記事の要点を整理します。
本記事では、まず日本企業の生成AI活用方針の策定率が49.7%にとどまり、特に中小企業でガバナンスの遅れが顕著であること、そしてガイドライン不在の環境で実際に情報漏洩事故が発生していることを確認しました。
次に、AI事業者ガイドライン、JDLAのひな形、IPAのセキュリティガイドライン、文化庁の著作権に関する考え方など、策定時に参照すべき公的文書を整理しました。これらの文書を土台に、社内ガイドラインに盛り込むべき10の構成要素と、5つの策定ステップを具体的に解説しました。
そして最後に強調したいのは、ガイドラインの策定は「スタート地点」に過ぎないということです。形骸化、ベンダー依存、自己評価の限界──これら運用段階の落とし穴を避けるためには、PDCAを回し続ける仕組みと、客観的・中立的な外部の視点が必要です。
ガイドラインを「作って終わり」にしないために
Aixisは、AIツールの選定・運用に関する第三者監査サービスを提供しています。ベンダーから完全に独立した中立的な立場で、貴社のAIガイドラインの実効性評価、ツール選定の客観的比較、運用リスクの監査を実施します。
「自社のガイドラインで本当に十分なのか確認したい」「ツール選定にベンダー以外の意見がほしい」──そうしたお悩みがございましたら、まずはお気軽にご相談ください。